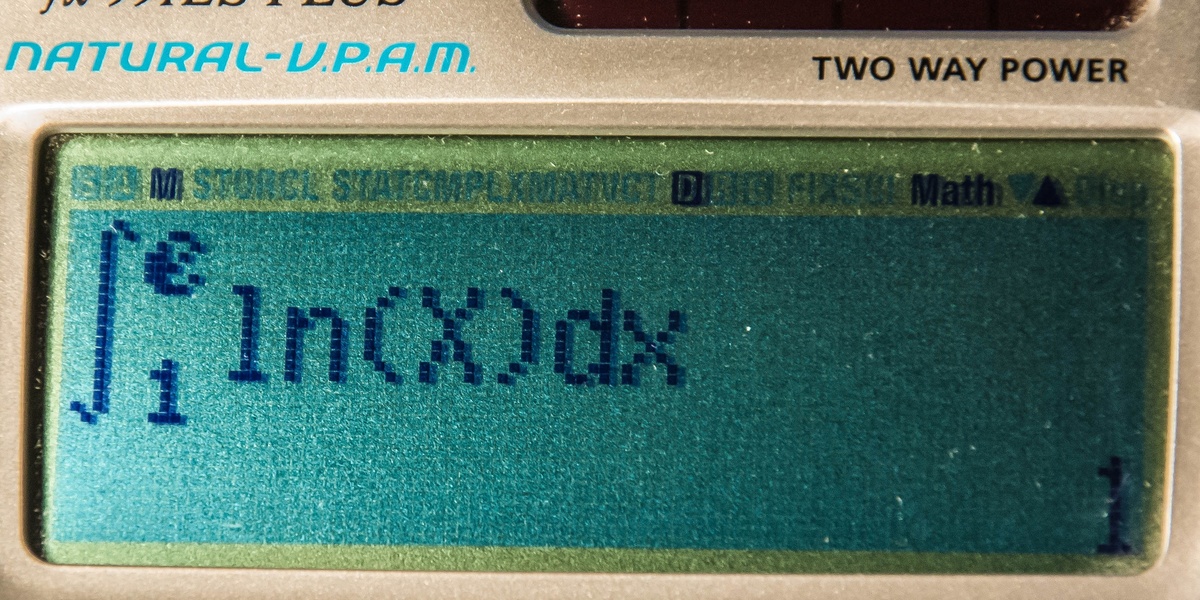
In the late 17th century Isaac Newton and Gottfried Wilhelm Leibniz developed calculus to describe motion and change; two centuries later, statisticians like Francis Galton and Karl Pearson formalized methods to analyze variability and populations. That sequence — late 1600s followed by major statistical advances in the 1800s and early 1900s — helps explain why the two fields feel so different.
Distinguishing calculus versus statistics matters for students choosing a major, engineers designing systems, and managers making data-driven decisions. Calculus teaches tools for rates of change and precise mathematical modeling; statistics teaches how to handle noisy measurements, sampling, and uncertainty. The choice affects how you reason about problems, the software you learn, and how results are communicated to stakeholders.
This piece lays out eight clear differences to help you decide what to study or apply. It compares rates of change vs uncertainty, mathematical modeling vs statistical inference, and practical workflows in both areas — ending with concrete next steps.
Conceptual Foundations
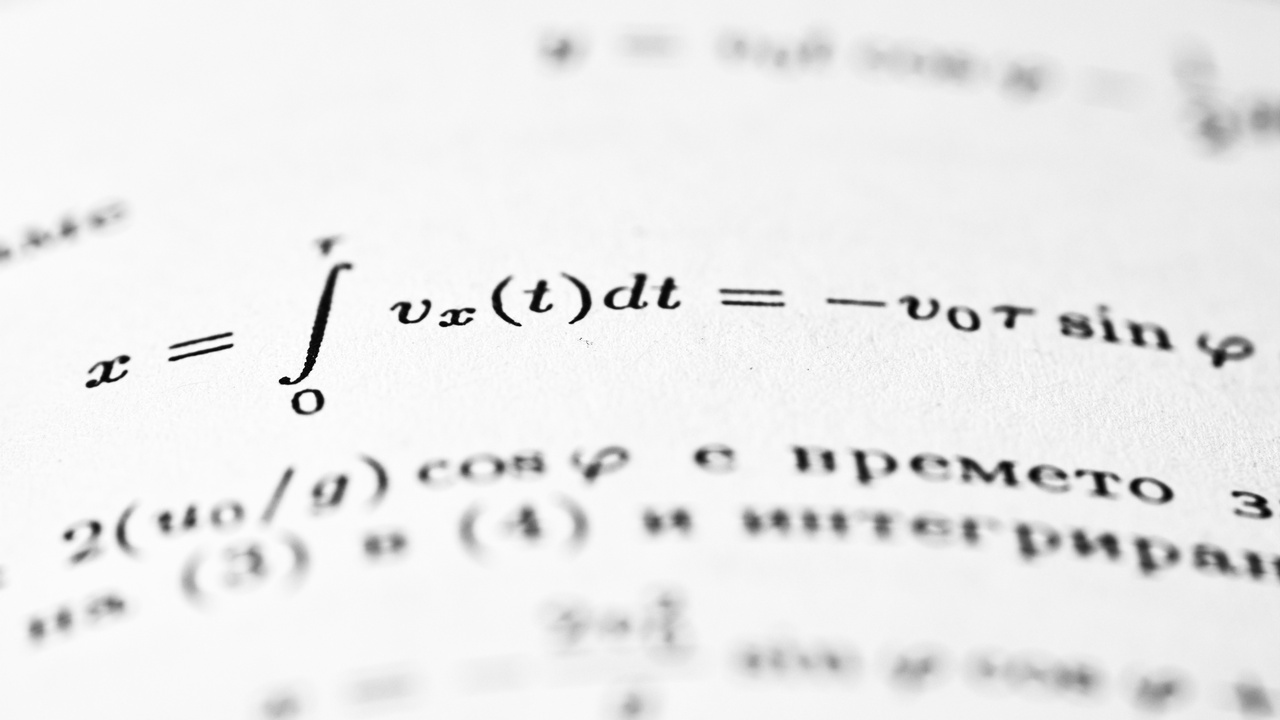
These points focus on the underlying questions and philosophical differences. One side treats systems as deterministic and governed by formulas; the other treats observations as samples from uncertain processes. Below we compare the questions they ask, the core mathematical objects they use, and how each justifies results.
1. Types of questions they answer (deterministic change vs probabilistic variation)
Calculus typically asks, “How does something change?” while statistics asks, “What can we say given variation and uncertainty?” Newton used calculus in the late 1600s to model planetary motion and falling bodies; modern engineers solve trajectories and flow rates with differential equations.
By contrast, a national poll of n≈1,000 respondents often reports a margin of error of about ±3% at 95% confidence — that’s a statistical answer about uncertainty, not an exact formula. Engineering calculations produce functions and closed-form results when assumptions hold; statistical work produces estimates, intervals, and probabilities for decisions in the face of noisy data.
2. Core objects: functions, limits, and derivatives vs random variables and distributions
Calculus centers on continuous objects: functions, limits, derivatives, and integrals. The Fundamental Theorem of Calculus (which links differentiation and integration) is a cornerstone that gives exact relationships between rates and accumulated quantities.
Statistics centers on random variables, probability distributions, samples, and estimators. Ideas behind the Central Limit Theorem emerged in the early 1800s and explain why sample means often look normal, which underpins many inference techniques. Those different core objects lead to different reasoning — limit-based proofs in calculus versus sampling-based approximations in statistics.
3. Role of proof and rigor vs modeling and inference
Calculus historically moved toward formal rigor in the 19th century with epsilon–delta definitions of limit and precise integral theory. Results are proven under explicit mathematical assumptions and yield exact conclusions when those assumptions hold.
Statistics evolved into a toolbox for messy, real-world data — R.A. Fisher’s methodological work in the 1920s shaped modern inference. Practitioners choose models, check assumptions, and report uncertainty; the emphasis is on applicability rather than pure proof. The trade-off is clear: exactness when the math fits versus usable estimates when data dominate.
Methods and Tools
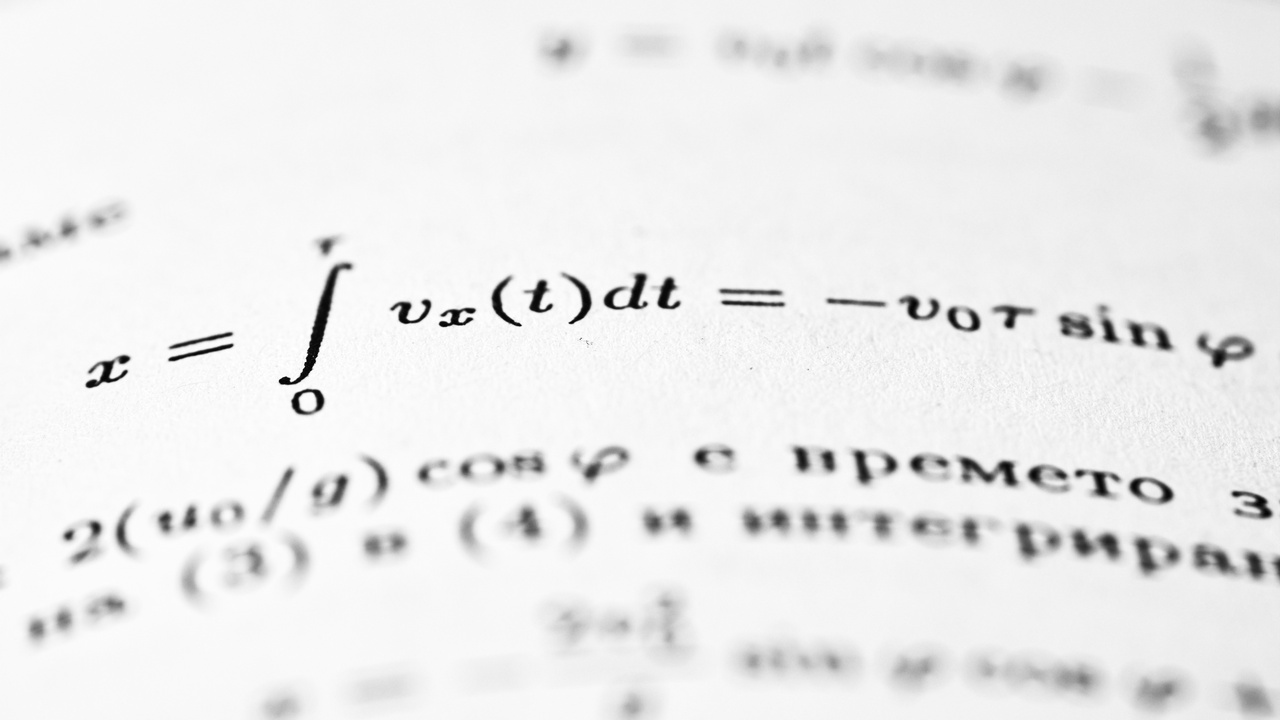
Tools and techniques diverge: calculus relies on symbolic manipulation and analytic methods; statistics leans on data-driven algorithms, estimation procedures, and hypothesis tests. Both areas use computation heavily, but the workflows and software ecosystems differ in predictable ways.
4. Main techniques: differentiation and integration vs estimation and hypothesis testing
In calculus the workhorse techniques are derivatives (rates), integrals (accumulations), and differential equations. In applied statistics the core moves are point estimation, confidence intervals, regression, and hypothesis tests such as Student’s t-test (first described in 1908) and chi-square tests.
Practically, engineers use gradients to optimize an aircraft wing shape; data scientists use regression and t-tests to compare groups. Stats often report p-values with a conventional threshold of p=0.05 to judge significance, while calculus delivers formulas and exact numerical solutions when an analytic approach applies.
5. Data requirements and assumptions: when each method applies
Calculus depends on mathematical regularity — continuity and differentiability — so techniques fail at nondifferentiable points (think absolute value at 0). Those are structural assumptions about functions, not the data used to estimate them.
Statistics depends on data quality and sampling assumptions: independence, representativeness, and sufficient sample size. For example, a proportion estimated from n≈1,000 has roughly a ±3% margin of error at 95% confidence, while n≈400 gives about ±5%. Practitioners plan sample size to shrink uncertainty; engineers validate model assumptions to ensure calculus results apply.
6. Tools and software: symbolic math vs data-driven ecosystems
Symbolic algebra systems like Mathematica and Maple are built for exact manipulation and closed-form solutions. For many calculus problems they’re the quickest route to an analytic integral or a symbolic derivative.
Statistics workflows favor R (initial release in 1993) and Python stacks (pandas, NumPy, SciPy, statsmodels) for data wrangling, estimation, and resampling (bootstrapping). A typical calculus workflow: derive an integral symbolically in Mathematica. A typical stats workflow: load data in R, run regression, and bootstrap confidence intervals.
Applications and Outcomes
Choosing between calculus and statistics often comes down to the problem: are you designing a deterministic system or making decisions from noisy measurements? The former favors differential equations and analytic models; the latter favors sampling plans, inference, and uncertainty quantification.
7. Typical applications: physics and engineering vs medicine, social sciences, and business
Calculus dominates fields that model continuous systems: physics, electrical and mechanical engineering, and classical fluid dynamics. Designers solve differential equations to predict currents, stresses, and trajectories in aircraft and circuits.
Statistics is central in public health, medicine, economics, and business analytics. For instance, COVID-19 vaccine efficacy studies in 2020–2021 reported point estimates with 95% confidence intervals to convey uncertainty, and agencies like the CDC rely on those inferential methods to guide policy.
8. Nature of certainty: exact solutions vs quantified uncertainty
Calculus aims for precise symbolic or numeric solutions under its assumptions: you can often compute an exact integral or the closed-form solution to a differential equation. That precision makes it appealing where tolerances matter.
Statistics produces estimates with quantified uncertainty. A study might report “the mean increase is 2.4 units, 95% CI [1.2, 3.6]” and possibly a p-value below 0.05. Communication is about ranges and probabilities rather than a single exact answer, which changes how results are interpreted and acted on.
Overall, the practical differences between calculus and statistics influence not just techniques but how results are presented to stakeholders and used in decision-making.
Summary
- Calculus asks precise questions about rates and accumulation; statistics answers questions about variability and inference from samples.
- Core math differs: derivatives, integrals, and limits versus random variables, distributions, and estimators.
- Tools and workflows diverge: symbolic systems for analytic solutions; R/Python and resampling for data-driven inference.
- Outcomes differ in certainty: exact solutions when assumptions hold versus estimates reported with confidence intervals and p-values.
- If you want concrete next steps: try modeling a projectile with differential equations (calculus), or analyze a real dataset with regression in R (statistics). Khan Academy has solid introductory calculus, and an introductory R course or CRAN resources will get you started in applied statistics.